
I didn’t know about that movie. Funny. Will try to remember to use the poster in a databases course ;-)
I didn’t know about that movie. Funny. Will try to remember to use the poster in a databases course ;-)
Andrew writes about Python, Perl and Ruby:
Ruby has some nice things (like Perlish regular expression handling), but it brings back all that punctuation noise again.
He gives an example of punctuation noise in Perl:
I go back to Perl and my eyes bleed after trying to dereference a reference to a scalar, or something like that. It’s just ugly in Perl.
I don’t think that’s fair to compare Perl’s ponctuation noise with Ruby. Ruby has a feature that could qualify as punctuation noise, but it’s really a feature: variables are prefixed with their scope. For example, class variables start with @@ (@@var), instance variables start with @ (@var), global variables start with $ ($var), and constants are in CAPS.
I don’t know if Ruby “invented” that, or if it comes from another language (it’s probably the case: Ruby takes a lot of good ideas everywhere).
Also, Andrew, joining elements of an array in ruby is written myarray.join(” “), and Ruby has =~. So you should definitely give Ruby a try ;) No, seriously, Ruby is a really interesting language. It’s really a shame that it’s still so japanese-centric (most development decisions are taken on a japanese mailing list !!), since it’s not really help a wide adoption.
The current status of the NM process, with 1 NM awaiting FD approval, 7 awaiting DAM approval, and 30 waiting for their accounts to be created, leads people to thinking that the big bottleneck is the account creation stage. However, when you look at what happened since december 2005, it’s not that simple.
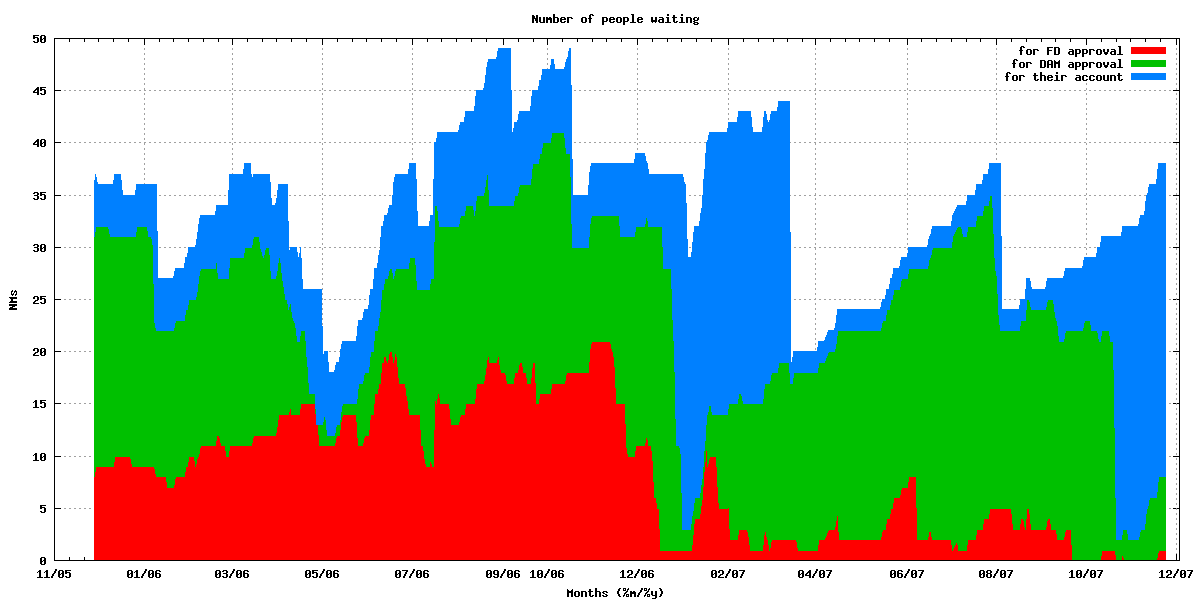
See the graph linked above, which shows where people are waiting. While it seems that the FD stage hasn’t been blocking people for nearly a year, it’s the DAM stage which has been the biggest blocker. Indeed, on average, 8.3 NMs have been blocked by FD, 16.2 by DAM, and 9.0 by account creation.
I understand that processing NM reports in batch mode makes it more efficient. However, I’m wondering if processing them 20 per 20, is really that more efficient than processing them 5 per 5, which would justify such long queues. The NEW queue, which used to be a problem, is now being processed on a very regular basis, and hasn’t grown widely recently, except after Debconf when the ftpmaster processing NEW was on VAC. Couldn’t we have the same thing for DAM, account creations, and while we are at it, removals from unstable? Having clearly defined human-crontab-jobs would certainly make working on Debian less frustrating.
This morning’s SuperComputing’07 keynote was a talk by Neil Gershenfeld, director of the Center for Bits and Atoms at the MIT. He mentioned the MIT Fab Labs, a project to bring “Personal Fabrication” to people around the around.
At our own level, that’s something I find very exciting with Free Software: it empowers people to do things with their computers that they couldn’t do if they were using proprietary software, simply because proprietary software is built to fit most people’s needs, not very specific goals some people could have. (and this is similar to the Long Tail stuff, in some ways)
Also, if you are at SC07 and reading this, feel free to ping me! I haven’t seen a lot of Debian/Ubuntuers here, even if the Free/Proprietary software ratio is very high.
NEW is currently nearly empty (only 3 packages), and there are only 2 NMs waiting for DAM approval. Some people deserve beers (… or milk ;) )!
There’s an interesting article on LWN.net about Gentoo: Who made Gentoo Linux, and when? A commit analysis
I was wondering how Debian compared, so I made some stats using the debian-devel-changes archives.
First, the number of source uploads per quarter:
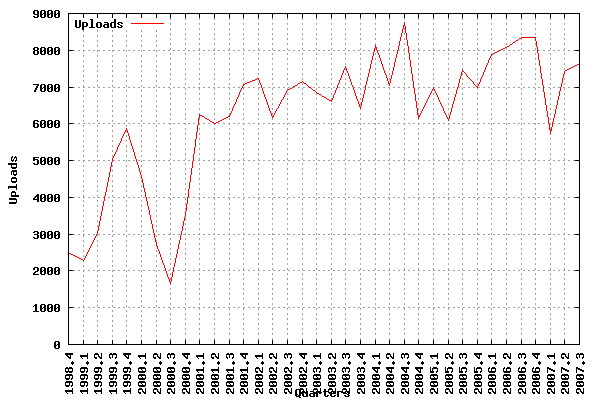
It’s interesting to note that, while the number of packages in Debian increased a lot, the number of uploads basically stayed the same since 2001.
Then, I wondered about the number of active developers in Debian. So I counted:
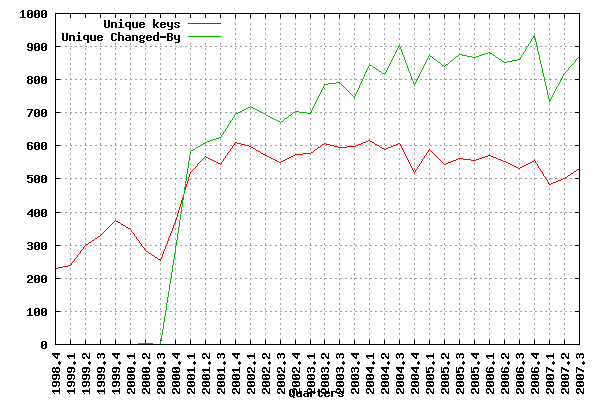
I can provide the raw data on demand, if someone else want to work on this. There’s probably a lot of other interesting things to do!
I recently sponsored several uploads, and was asked to sponsor even more uploads, and that got me thinking about our sponsorship workflow. It’s a clear bottleneck in Debian, and discourages many new contributors, which obviously sucks.
It’s important to note that the same problems exist in Ubuntu (their equivalent to mentors.debian.net is named REVU).
The best way to improve the process would be to have packages of better quality when a DD first look at them. They would be more likely to be uploaded right away, which frees time for other packages. I think that there’s a lot of room for improvement in the current mentors.debian.net implementation. Here is a small list of features I would like to see.
This would allow potential sponsors to prioritize requests.
The good thing with this whole list of features is that everybody can help. So, if you are looking for a sponsor and want to help solve this problem, start coding now ;) And if you need me to create nicenameforyourservice.debian.net, just ping me. There’s probably some code to steal from svnbuildstat.debian.net, so contacting its developers would be a good idea.
Christian Perrier is wondering why the official announcement about the Gutsy release does not even contain the word “Debian”.
It’s not new: Debian is virtually nonexistent in Ubuntu’s communication. It seems that the last Ubuntu release to acknowledge its Debian origins was Dapper (June 2006), maybe because that was the “Long Term Support” release.
The fact that there’s no “Ubuntu is based on Debian” paragraph on www.ubuntu.com was raised during Debconf, and it was supposed to get fixed, but it seems that it didn’t happen for some reason (there was such a paragraph before the website redesign).
In other news, I’ve been trying to install Ubuntu Gutsy inside qemu, but it fails miserably while booting the installer. I removed the “quiet” and “splash” options from the kernel cmdline, and discovered that after trying to “mount the root filesystem”, I get dropped into busybox with no error message to google for. Feisty fails as well, but Dapper boots fine. So much for the Ubuntu is an ancient African word, meaning “I can’t install Debian” joke!
Donnie Berkholz wrote an interesting article on Who made Gentoo Linux, and when?. Has someone already done something similar for Debian? It would probably be possible (and easy) to use the debian-devel-changes archives (available since 1998) for that.
In a lot of talks or blog posts (like Sam’s talk at RMLL, or Raphaël’s blog posts – both in french), people have been talking about what people could do inside Debian, and how it would help Debian.
That doesn’t sound like the best approach to me. When describing tasks with the objective of getting potential contributors to pick them up, we should try to make them sexy, to tell users what is exciting about them, what they will learn doing those tasks, where satisfaction will come from. We really need to sell them better.
Of course, some Debian tasks are mainly grunt work. And for some of them, people just do them because someone has to do them. But I believe that most tasks inside Debian are actually more interesting than outsiders would expect. For example, I would be very interested in reading why an i18n expert (hint: Christian!) finds i18n sexy … and I should probably try to write about QA myself.
(As you might have noticed now, the subject of this blog post was misleading on purpose — chosen so that a lot of people would read the post :P)