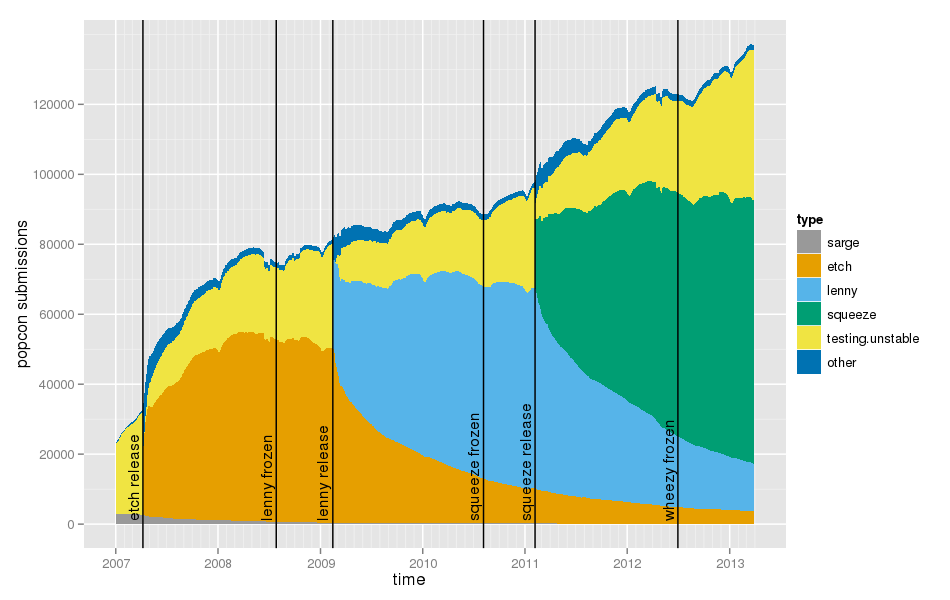
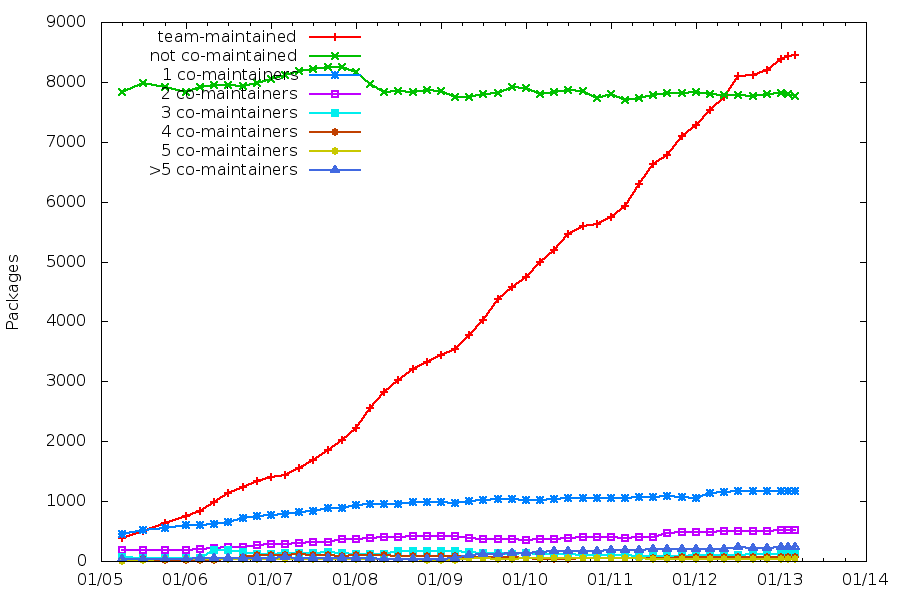
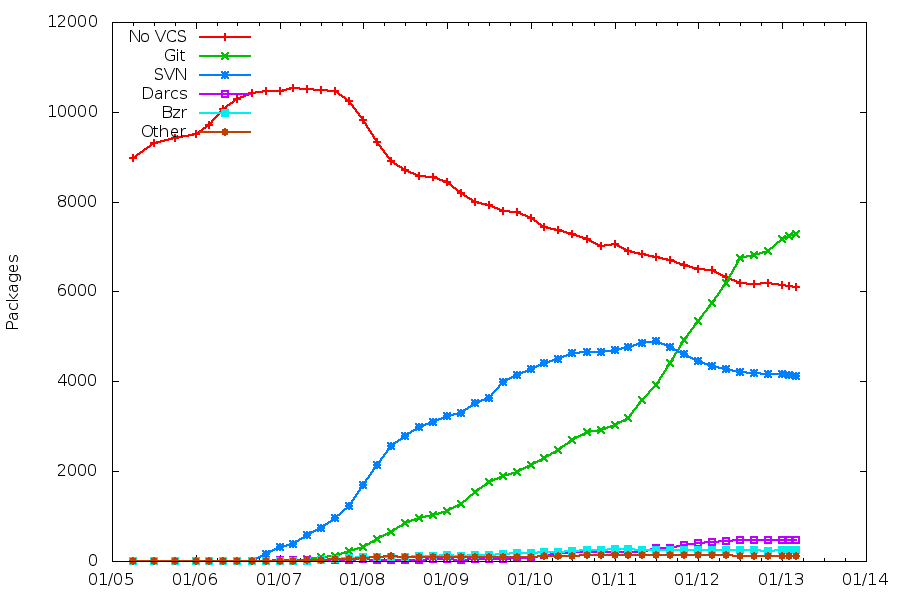
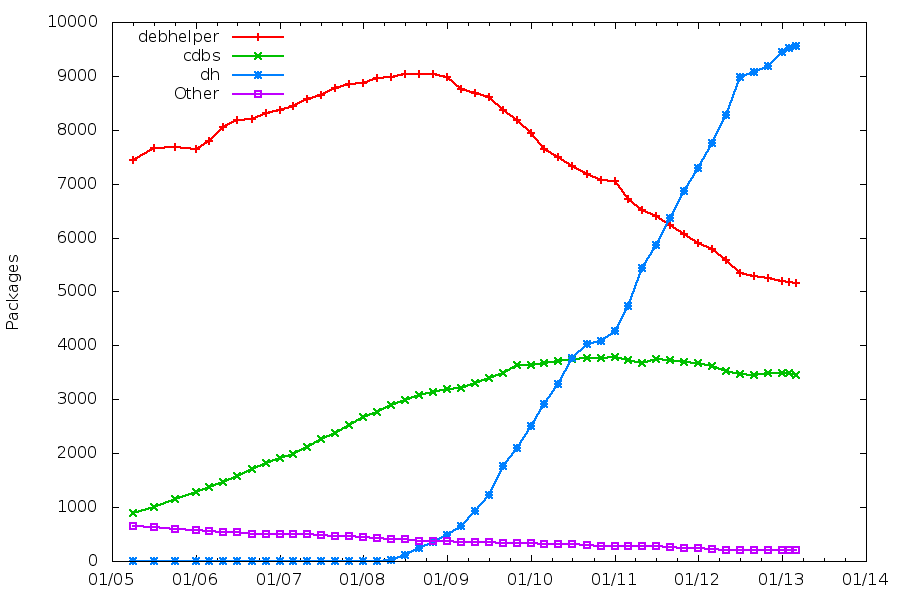
During the Paris Mini-Debconf, Nicolas Dandrimont talked about The state of mentors.debian.net: GSoC and beyond. He said that Half of Debian’s packages are maintained by sponsored maintainers. That statement was actually wrong, as he confirmed later.
However, using a few UDD queries, I could come up with:
- 3147 packages out of 18649 packages in sid (17%) were last uploaded using a sponsored upload.
- There are 963 distinct sponsorees, vs. a total of 2015 distinct emails in the Changed-By field of packages in sid. Given that it’s more likely for DDs to have used several emails to upload packages, it’s very likely that half of the package maintainers are sponsored maintainers.
- There are 2185 packages without a DD in either the Maintainer: or the Uploaders: fields. (That includes some packages that are maintained by a team that could include some DDs)
Full UDD notes:
all packages in sid:
select source, version from sources_uniq where release = 'sid'
packages in sid known to upload_history:
select source, version from upload_history where
(source, version) in (select source, version from sources_uniq where release = 'sid')
packages that were uploaded by the changed_by person:
create temporary table sources_not_sponsored as select distinct source, version
from upload_history, carnivore_keys, carnivore_emails
where (source, version) in (select source, version from sources_uniq where release = 'sid')
and fingerprint = key
and carnivore_keys.id = carnivore_emails.id
and carnivore_emails.email = changed_by_email;
packages not uploaded by the changed_by person:
create temp table uh_sid as select source, version, fingerprint, changed_by_email
from upload_history
where (source, version) in (select source, version from sources_uniq where release = 'sid');
create temp table uh_sid_sponsored as select source, version, fingerprint, changed_by_email from uh_sid
where (source, version) not in (select source, version from sources_not_sponsored);
list with sponsor login:
select distinct source, version, fingerprint, changed_by_email, login
from uh_sid_sponsored
left join carnivore_keys on fingerprint = key
left join carnivore_login on carnivore_keys.id = carnivore_login.id;
=> 4188 sponsored packages. some of them are in a strange state (changed_by is a DD, but uploaded by another DD). excluding those:
create temp table sponsored_but_dds as select distinct source, version, fingerprint, changed_by_email, login
from uh_sid_sponsored, carnivore_emails, carnivore_login
where changed_by_email = carnivore_emails.email
and carnivore_emails.id = carnivore_login.id;
create temp table really_sponsored as select distinct source, version, fingerprint, changed_by_email, login
from uh_sid_sponsored
left join carnivore_keys on fingerprint = key
left join carnivore_login on carnivore_keys.id = carnivore_login.id
where (source, version) not in (select source, version from sponsored_but_dds);
=> 3147 sponsored packages
select distinct changed_by_email from really_sponsored ;
=> 963 different sponsorees
select distinct changed_by_email from upload_history where
(source, version) in (select source, version from sources_uniq where release = 'sid');
=> 2015 distinct emails.
no DD amongst maintainer or uploader:
create temp table dds_emails as select email from carnivore_emails, carnivore_login
where carnivore_emails.id = carnivore_login.id;
select source, version, maintainer, uploaders from sources_uniq
where release='sid'
and maintainer_email not in (select * from dds_emails)
and not exists (select * from uploaders where release = 'sid' and sources_uniq.source = uploaders.source and sources_uniq.version = uploaders.version and email in (select * from dds_emails))
and maintainer_email != 'packages@qa.debian.org'
and (source, version) in (select source, version from really_sponsored);