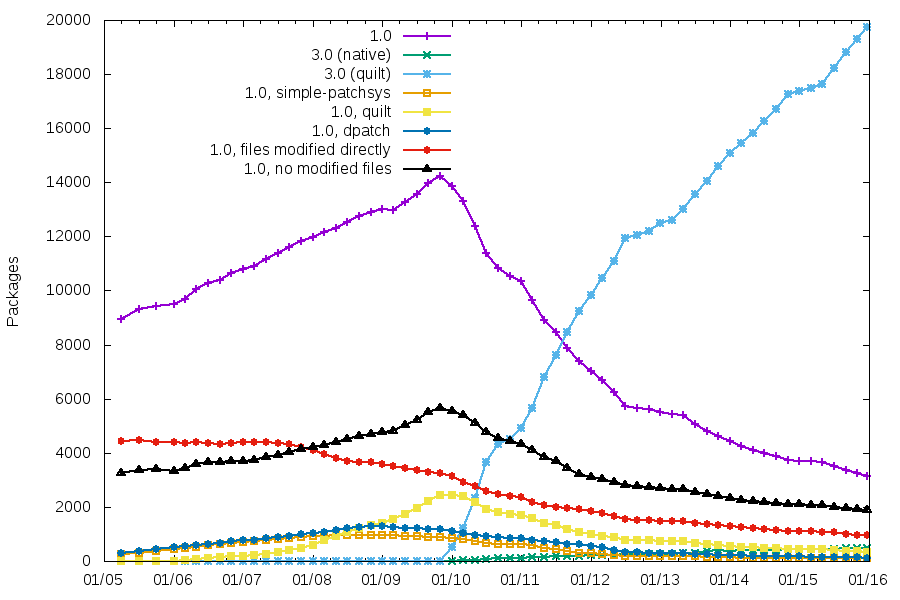
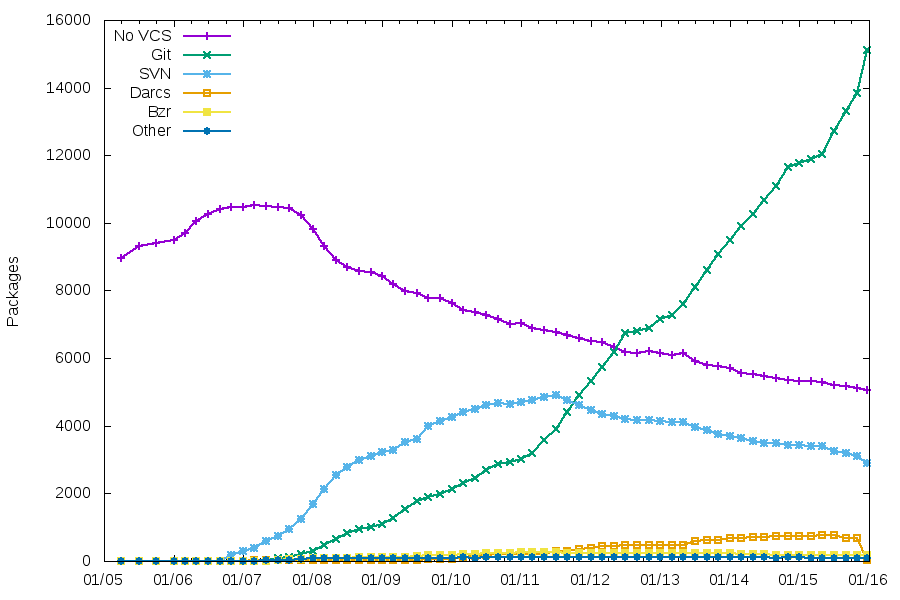
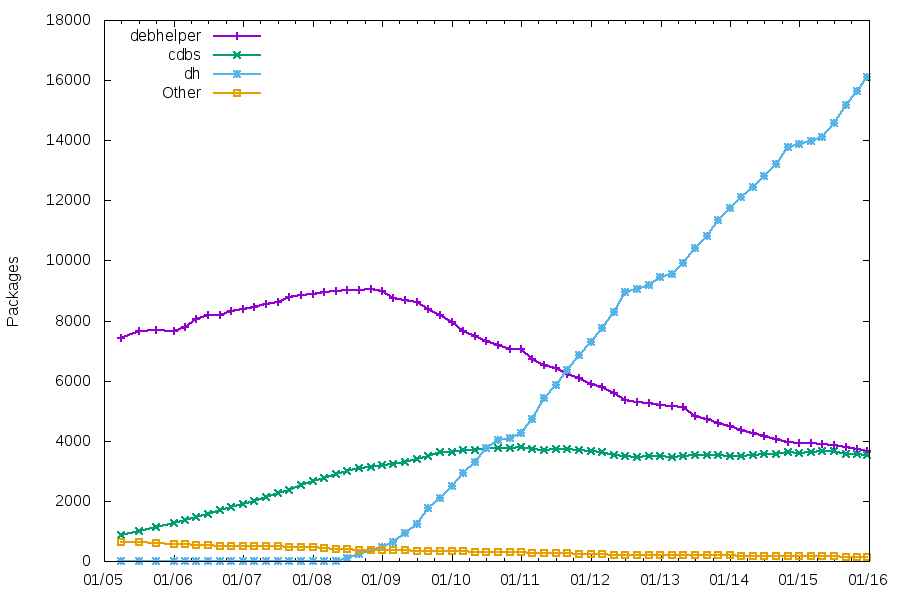
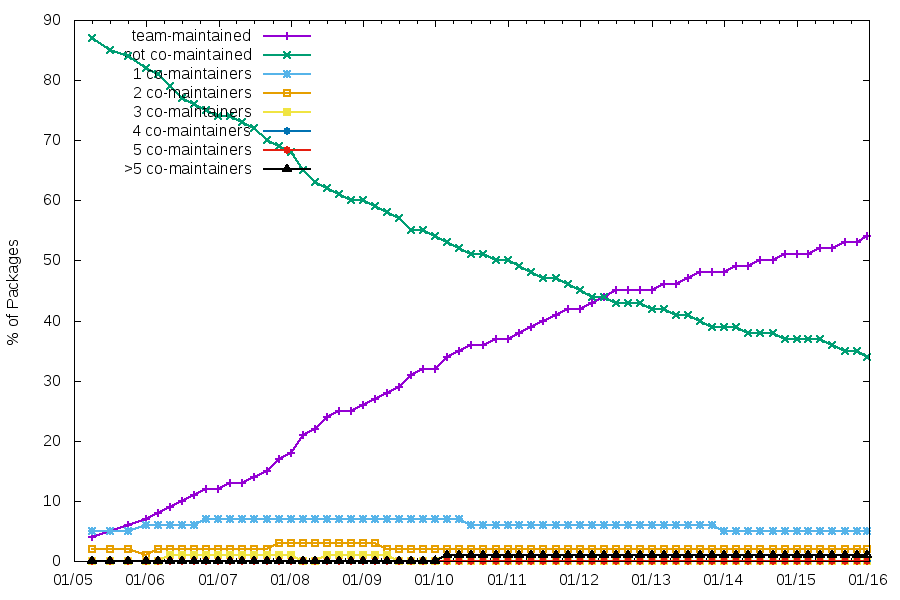
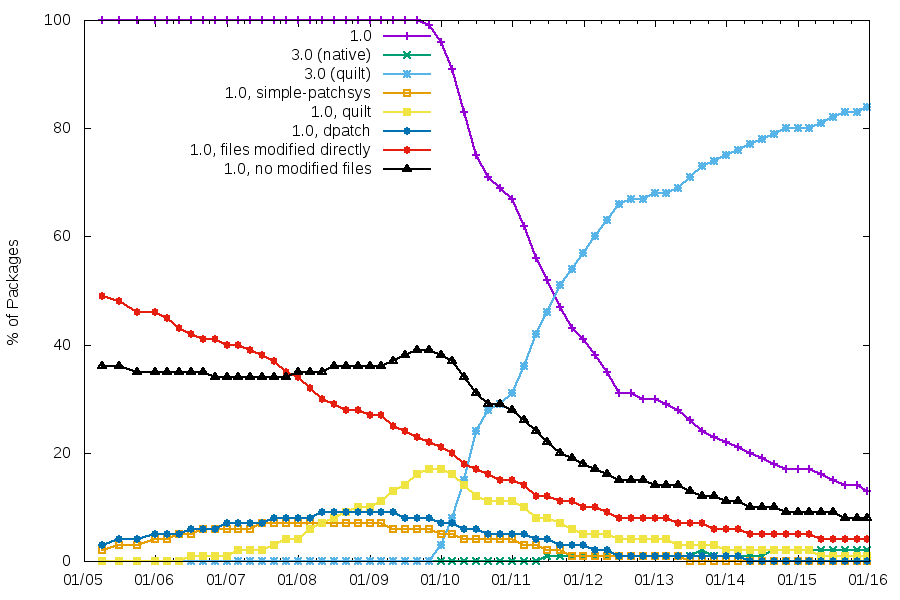
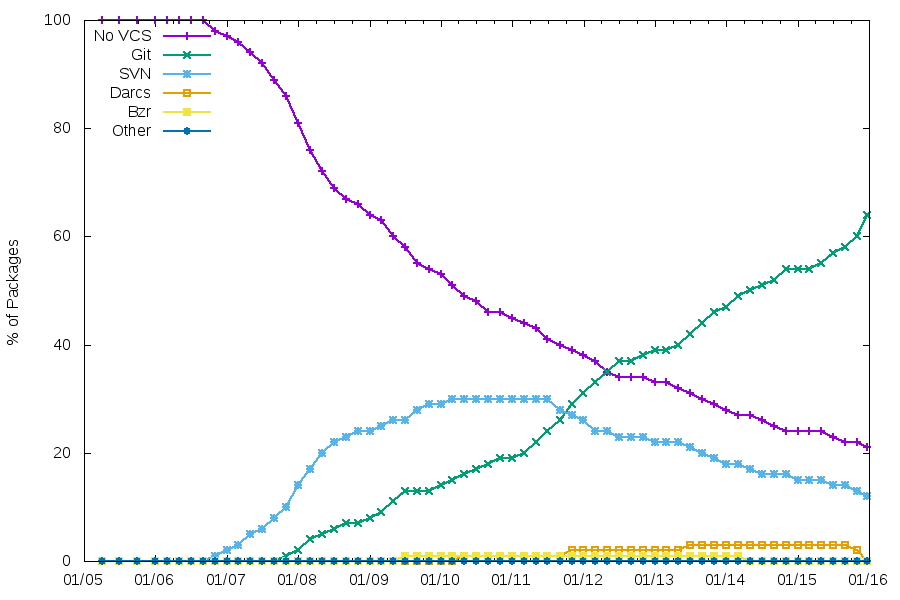
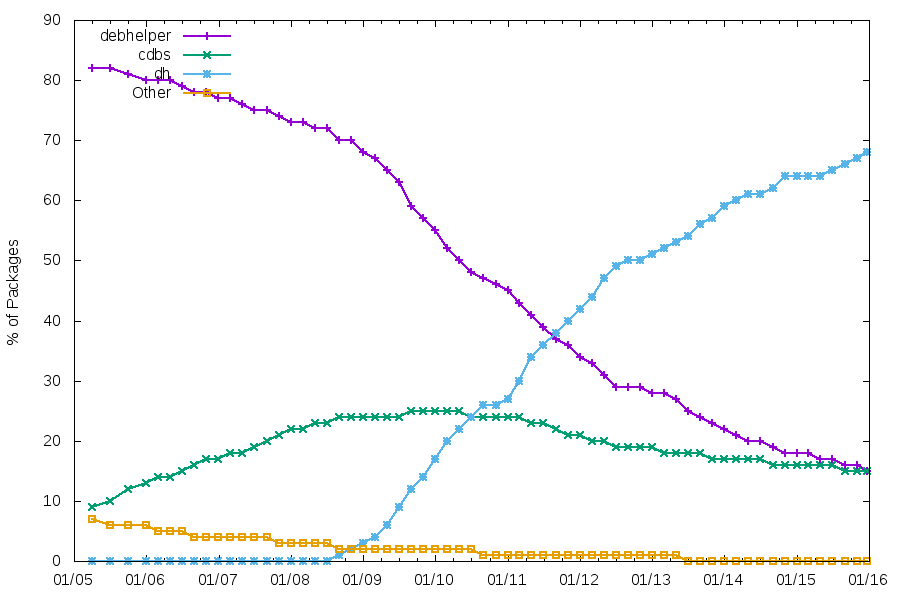
There’s a pattern that comes up from time to time in the release management of free software projects.
To allow for big, disruptive changes, a new development branch is created. Most of the developers’ focus moves to the development branch. However at the same time, the users’ focus stays on the stable branch.
As a result:
- The development branch lacks user testing, and tends to make slower progress towards stabilization.
- Since users continue to use the stable branch, it is tempting for developers to spend time backporting new features to the stable branch instead of improving the development branch to get it stable.
This situation can grow up to a quasi-deadlock, with people questioning whether it was a good idea to do such a massive fork in the first place, and if it is a good idea to even spend time switching to the new branch.
To make things more unclear, the development branch is often declared “stable” by its developers, before most of the libraries or applications have been ported to it.
This has happened at least three times.
First, in the Linux 2.4 / 2.5 era. Wikipedia describes the situation like this:
Before the 2.6 series, there was a stable branch (2.4) where only relatively minor and safe changes were merged, and an unstable branch (2.5), where bigger changes and cleanups were allowed. Both of these branches had been maintained by the same set of people, led by Torvalds. This meant that users would always have a well-tested 2.4 version with the latest security and bug fixes to use, though they would have to wait for the features which went into the 2.5 branch. The downside of this was that the “stable” kernel ended up so far behind that it no longer supported recent hardware and lacked needed features. In the late 2.5 kernel series, some maintainers elected to try backporting of their changes to the stable kernel series, which resulted in bugs being introduced into the 2.4 kernel series. The 2.5 branch was then eventually declared stable and renamed to 2.6. But instead of opening an unstable 2.7 branch, the kernel developers decided to continue putting major changes into the 2.6 branch, which would then be released at a pace faster than 2.4.x but slower than 2.5.x. This had the desirable effect of making new features more quickly available and getting more testing of the new code, which was added in smaller batches and easier to test.
Then, in the Ruby community. In 2007, Ruby 1.8.6 was the stable version of Ruby. Ruby 1.9.0 was released on 2007-12-26, without being declared stable, as a snapshot from Ruby’s trunk branch, and most of the development’s attention moved to 1.9.x. On 2009-01-31, Ruby 1.9.1 was the first release of the 1.9 branch to be declared stable. But at the same time, the disruptive changes introduced in Ruby 1.9 made users stay with Ruby 1.8, as many libraries (gems) remained incompatible with Ruby 1.9.x. Debian provided packages for both branches of Ruby in Squeeze (2011) but only changed the default to 1.9 in 2012 (in a stable release with Wheezy – 2013).
Finally, in the Python community. Similarly to what happened with Ruby 1.9, Python 3.0 was released in December 2008. Releases from the 3.x branch have been shipped in Debian Squeeze (3.1), Wheezy (3.2), Jessie (3.4). But the ‘python’ command still points to 2.7 (I don’t think that there are plans to make it point to 3.x, making python 3.x essentially a different language), and there are talks about really getting rid of Python 2.7 in Buster (Stretch+1, Jessie+2).
In retrospect, and looking at what those projects have been doing in recent years, it is probably a better idea to break early, break often, and fix a constant stream of breakages, on a regular basis, even if that means temporarily exposing breakage to users, and spending more time seeking strategies to limit the damage caused by introducing breakage. What also changed since the time those branches were introduced is the increased popularity of automated testing and continuous integration, which makes it easier to measure breakage caused by disruptive changes. Distributions are in a good position to help here, by being able to provide early feedback to upstream projects about potentially disruptive changes. And distributions also have good motivations to help here, because it is usually not a great solution to ship two incompatible branches of the same project.
(I wonder if there are other occurrences of the same pattern?)
Update: There’s a discussion about this post on HN